Building a Local Multimodal Video RAG System - Python PoC and Memory Bottlenecks
Introduction
Recently, I’ve been exploring how to build a fully localized, privacy-preserving Multimodal Retrieval-Augmented Generation (RAG) system. My specific use case was indexing non-standard animated videos (like Chiikawa) that don’t have embedded subtitles.
While existing solutions rely heavily on cloud APIs, I wanted to prove that a completely local pipeline is possible on edge devices. Thus, this Python-based Proof-of-Concept (PoC) was born.
System Architecture
The system relies on a pipeline of OpenCV -> LLaVA (Ollama) -> Gemma 2 -> Nomic Embeddings.
(You can view the detailed system architecture diagram on my GitHub Repository)
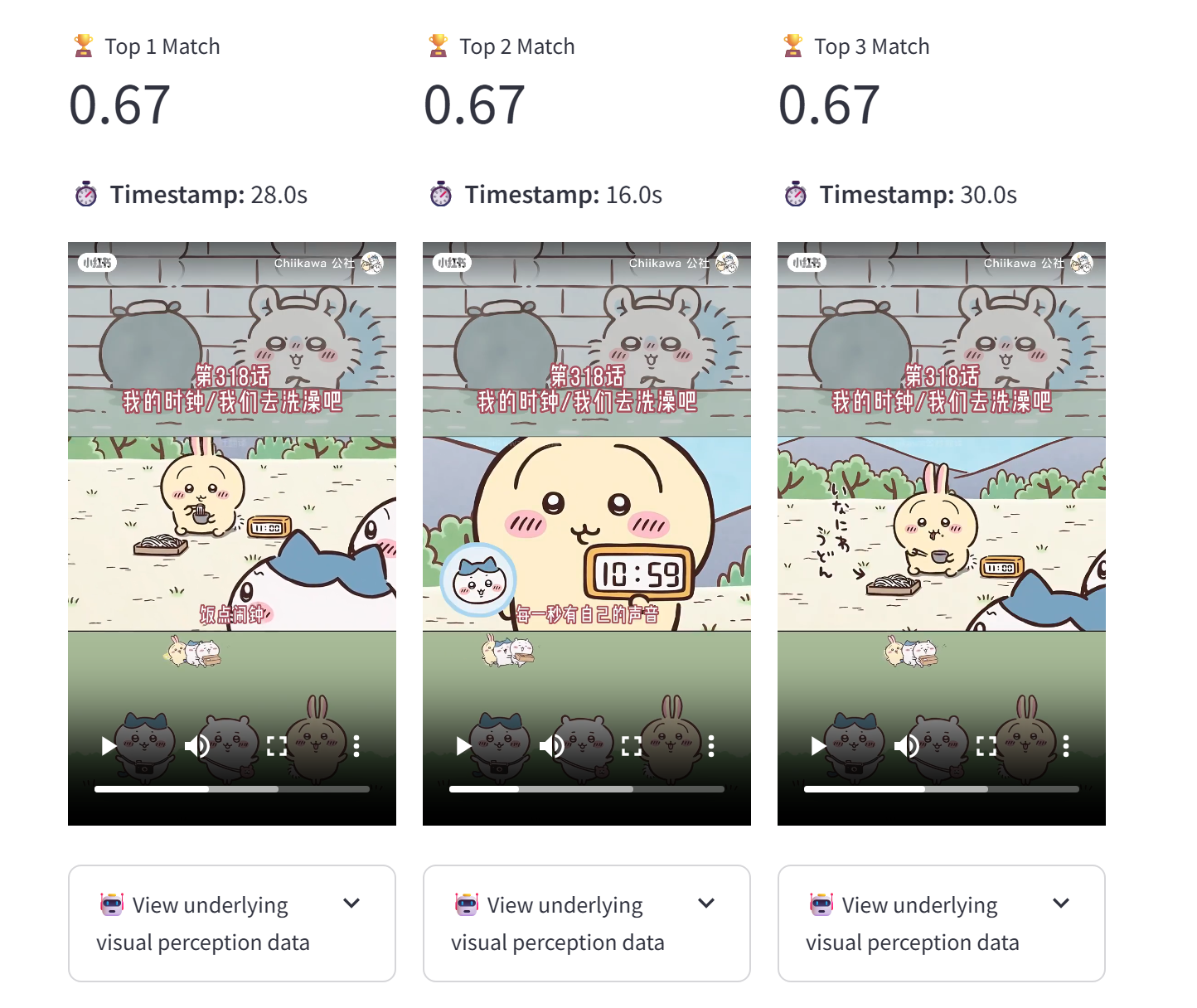
UI Demo & Cross-Lingual Search
One of the most interesting parts of this project was using Gemma 2 for query routing. For example, if a user searches for “乌萨奇” (Chinese), the system translates and optimizes it into English before performing the vector search.

Future Evolution
The current Python-based implementation served its purpose as a functional Proof-of-Concept. However, during the stress tests, I observed significant performance bottlenecks—specifically the Python Global Interpreter Lock (GIL) overhead and memory spikes when handling high-density frame ingestion.
As a next step, I am planning a native architectural migration. Moving the core pipeline to C++ and leveraging OpenVINO for inference would allow for more granular resource management and zero-copy memory operations on edge devices. For me, this project is not just about searching videos; it’s a deep dive into the trade-offs between rapid prototyping and production-grade performance.
Conclusion: Pure Python is excellent for rapid prototyping, but pushing edge AI to production demands stricter resource control. Moving forward, I plan to explore migrating the core ingestion pipeline to a C++ Native Architecture (potentially with OpenVINO) to bypass the GIL and eliminate memory overhead. This will be a challenging but necessary evolution for the system.